malloc在glibc中的实现原理
在C++编程中,可以通过 new/delete 或 new[]/delete[] 在堆上进行内存分配和释放。Linux环境下,这些操作中的内存分配和释放往往由glibc中的 malloc()/free() 函数实现。在C编程中,更是直接通过 malloc()/free() 来进行堆上内存的分配和释放。
malloc作为操作系统和应用程序的中间层,向操作系统申请大块内存,按需求将其划分为小块内存分配到应用程序。在应用程序释放内存后,在整块内存可用时返回给操作系统。
这里我们对glibc中的malloc原理进行分析,以便分析其性能等特征。
malloc 基本概念
在对malloc的原理进行分析前,我们首先看一看其中的一些关键概念。
内存(Memory):应用程序的一段地址空间,这段空间通常映射到物理内存或swap。
块(Chunk):可以被分配给应用程序、释放回glibc的小块内存,相邻的小块可以合并为一个大块。
堆(Heap):可以划分为多个用于分配的块的连续内存区域。每个堆关联且只关联到一个分配区(Arena)。
分配区(Arena):可以在一个或多个线程间共享的结构,其中含有:到一个或多个堆(Heap)的引用,堆(Heap)中空闲块的链表。线程会在所属的分配区(Arena)的空闲块链表中分配内存。
malloc 数据结构
为了便于管理Arena、Heap、Chunk,实现内存的分配和回收,malloc在内存中建立了对应的数据结构。下面我们结合分配和回收算法来介绍这些数据结构。
Chunk
Chunk是malloc内存分配与释放的单位。应用程序通过malloc申请内存时,glibc将一块Chunk中的地址返回给应用程序;应用程序释放内存时,将Chunk重新返还给glibc进行管理。
为了高效地实现Chunk的管理,Chunk中除用于应用程序使用的内存外,还包含一些额外的数据区。同时,在应用程序将Chunk归还给glibc后,glibc会在原本提供给应用程序使用的内存中再存储另一些额外数据。
下面我们通过一张图看一看Chunk在空闲和使用状态下的数据结构。
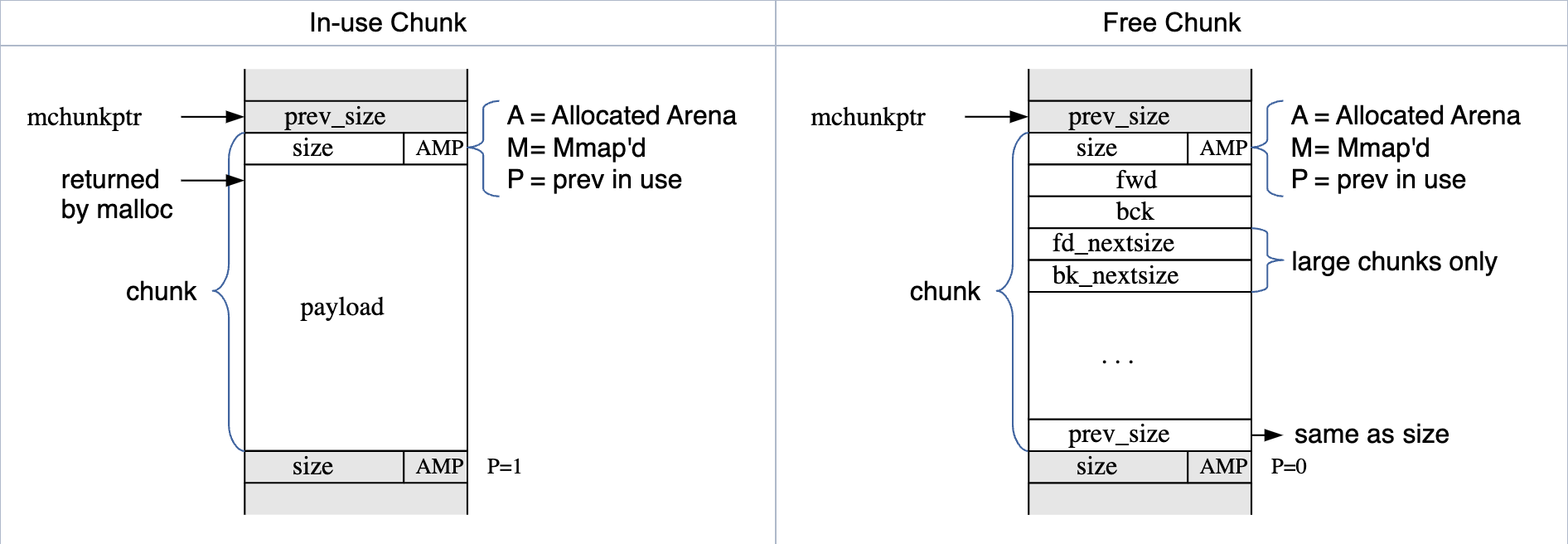
Note: 为了便于处理对齐问题,源代码中将prev_size放在了当前chunk结构中。也就是说,图中的mchunkptr才是chunk结构体的地址.
在已占用的Chunk中,共有两个部分:size和payload。
size字段为Chunk中的元数据,它以字节为单位记录了Chunk的大小(包括size字段本身)。由于Chunk大小总是8的倍数,size的的最低3位永远为0。因此,glibc将这3为作为标记位使用,表示Chunk的一些特征。
这些标记共A、M和P共3位。它们的如下:
A(0x04): Allocated Arena. 标识该Chunk处于后分配的Heap还是初始Heap。该位值为0表示这个块位于应用程序主arena下的首个Heap中,这意味着该块所在的Heap没有heap_info,也没有arena_info,全为Chunks。该位值为0则表明这个块位于mmap分配的后续堆中。这些堆的头部存储了heap_info结构体。由于堆地址对齐到 HEAP_MAX_SIZE (2^N) 大小,可以利用Chunk地址通过位运算快速定位到堆地址,并读取heap_info结构体内容。
M(0x02): Mmap’d. 标识该Chunk是否通过mmap直接分配、不属于任何堆。当申请超过 DEFAULT_MMAP_THRESHOLD 大小的内存块时,glibc通过mmap直接从操作系统申请一块内存来满足需求。这种直接从操作系统申请的块的M标记位即置为1. 而大多数情况下申请的小块内存则从堆中分配,则M标记位值为0.
P(0x01): prev in use. 标识该块前面的一个块是否正在使用。当前一个块正在使用时,该标记位值为1,且前一个块不能被合并成大块。(fastbins中的块也被认为在使用中,不能被合并。)此时该内存块的前一个内存块未被使用,prev_size可能为上一块的payload中的一部分,不能作为size用。当该标志位值为0时,可以在需要时合并为大块。
payload部分长度不固定,当块被分配给应用程序时,malloc返回的地址便在这一区域中。
在已释放的Chunk中,除size字段外,还在原本的payload区域中增加了几个额外的字段以便下次分配时快速找到空闲Chunk。这些字段包括fwd、bck、prev_size字段,在大Chunk中还有fd_nextsize、bk_nextsize两个字段。因为空闲块中的这些必要字段,Chunk有大小为 4*sizeof(void*) (size+fwd+bck+prev_size) 的最小大小。(这个最小大小可以为了对齐之类的原因采用更大的值。)
在Arena的数据结构中,维护了一批bins。空闲Chunk中的fwd、bck字段构成了多个双链表,这些双链表的头指针就存储在Arena的bins中。
大块Chunk中fd_nextsize、bk_nextsize字段则构成跳表,以便找到其他大小的空闲Chunk。
在空闲块的最后,存储了prev_size字段。它与Chunk头部的size相同,存储了当前块的大小,以字节为单位。与size不同的是,prev_size没有标志位,其最低的3位永远为0.
Note: 如上一个Note所言,源代码中prev_size是Chunk中的第一个字段,而不是像上图那样放在Chunk的尾部。这就是图中prev_size表示当前Chunk大小,却叫做prev_size的原因。
Arena
在多线程环境下,每个线程都可能有分配内存的需要。如果所有线程都在同一个结构下进行内存的分配和释放,在内存分配压力较大的情况下,就有较大的冲突概率。为了降低冲突概率,提高内存管理效率,glibc采用多个arena,将锁操作限制在同一个arena中。
因此,arena也需要维护自己的数据结构,以实现对这些arena的管理。下面我们通过一张简化的arena结构图来看看arena数据结构。
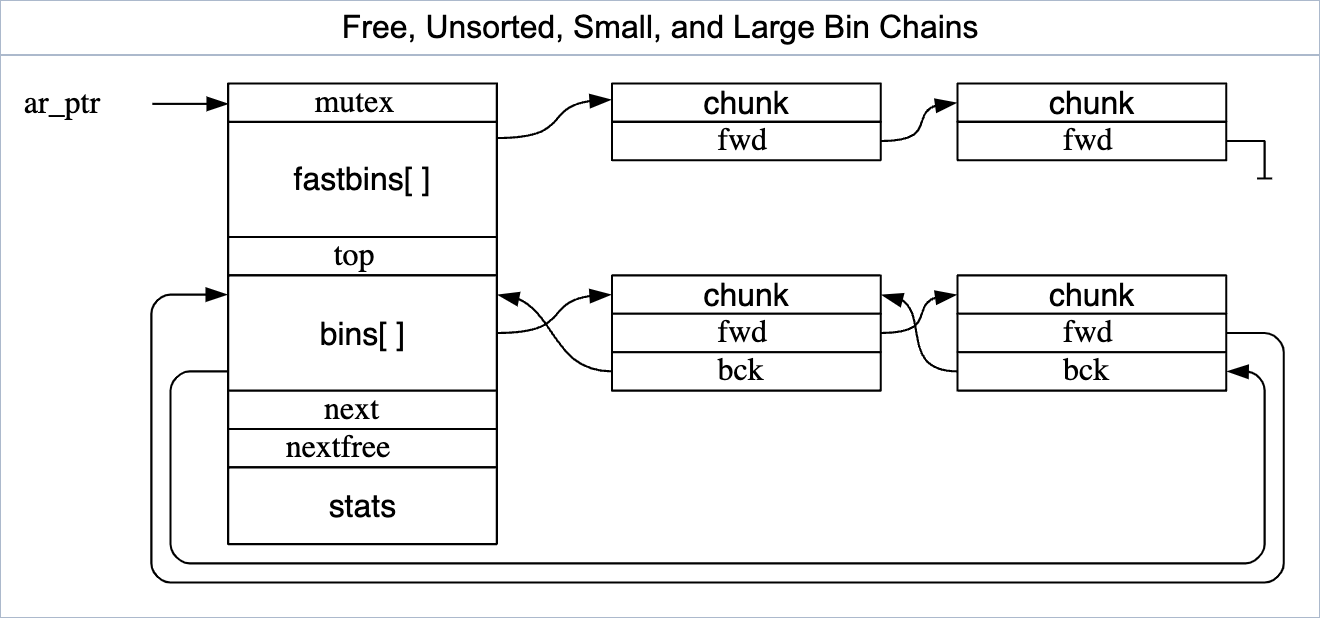
Note: 上图不是完整的arena结构,省略了一些字段。
每个arena结构中都有一个mutex,防止多个线程进行内存分配与释放时发生并发错误。对于arena的大多数操作都需要首先在该mutex上加锁,只有对fastbins的访问等少部分操作可以通过原子操作来完成而不需要加锁。
next和nextfree将arena连接为两条不同的链表。next将所有arena连接为一条链表。nextfree则将所有空闲的arena连接为一条链表。当需要挑选空闲arena时,将从nextfree中搜索。
fasbins和bins将arena管理的所有空闲Chunk连接成多条链表。应用程序释放的Chunk会根据其历史和大小插入对应的链表中。这些链表称为桶(bins)。
fastbins中引用的桶称为Fast bins. 小块的Chunk释放时便会插入这些桶中。为了提高对这些桶的操作效率,这些桶的管理只采用最简单的逻辑,不支持Chunk的合并。同时,其中每个桶只存储一种大小的Chunk,且可以通过Chunk大小在fastbins数组中快速找到对应的桶。在一个桶中,所有Chunk大小都相同,访问时取得任一Chunk均可。这样,中间节点不会被访问,也不会被删除,因此可以将其组织为单链表以获得最高的效率。
在bins中,则存储了Unsorted、Small和Large三类具有不同特点的桶。
Unsorted bins仅有一个,这个桶中存储的是各种大小的空闲Chunk。在应用程序释放相对较大的Chunk时,这些Chunk无法放入Fast bins,Small bins这样的只存储小块Chunk的桶中。这些具有不同大小的空闲Chunk便被简单地插入Unsorted bins中,并在后续分配中进行管理。这个无序的桶将空闲Chunk合并等工作推迟到其他的适当时机来执行,从而保证了大多数情况下的分配和释放效率。
Small bins与Fast bins类似,每个桶中只存储一种大小的Chunk。但与Fast bins不同的是,在其他Chunk分配时,Small bins中的Chunk可以被合并。当Chunk被合并时,就需要将该Chunk从Small bins中删除。为了支持这种从链表中任意位置快速删除节点的操作,Small bins使用双向链表的结构进行组织。
与Fast bins、Small bins不同,Large bins的每个桶中可以存储多种大小的空闲Chunk。这些大块的空闲Chunk在分配时很可能无法与申请的大小完美匹配,因此在需要时可以将空闲Chunk拆分为两块,一块提供给应用程序使用,剩下的重新插入这些管理结构中进行管理。为了避免不必要的拆分,找到最合适的Chunk,Large bins中的空闲Chunk除了原本的双向链表外,还维护了一条循环双向链表。这个链表采用类似“跳表”的方式,将不同的大小的Chunk进行连接,从而提高了寻找合适大小的Chunk的效率。这一结构如下图所示:
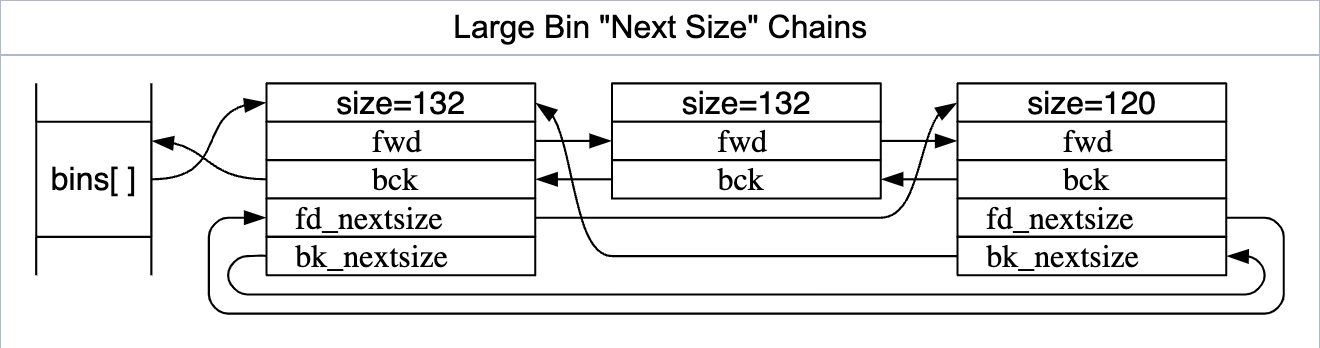
top字段指向一个大块的空闲Chunk,这个Chunk放在Arena中最新的Heap的高地址上。当无法从bins中分配到合适的内存时,glibc会从这个Chunk中拆分出新的空闲Chunk进行分配。
tcache
通过Arena进行内存分配时,需要通过原子操作或锁机制来实现线程安全。为了提升效率,glibc还维护了一组线程变量将部分Chunk保留在当前线程内。在进行内存的分配和释放时,首先尝试从这些线程变量中进行分配和释放。这些线程变量就称为tcache。它们的结构如下图所示:
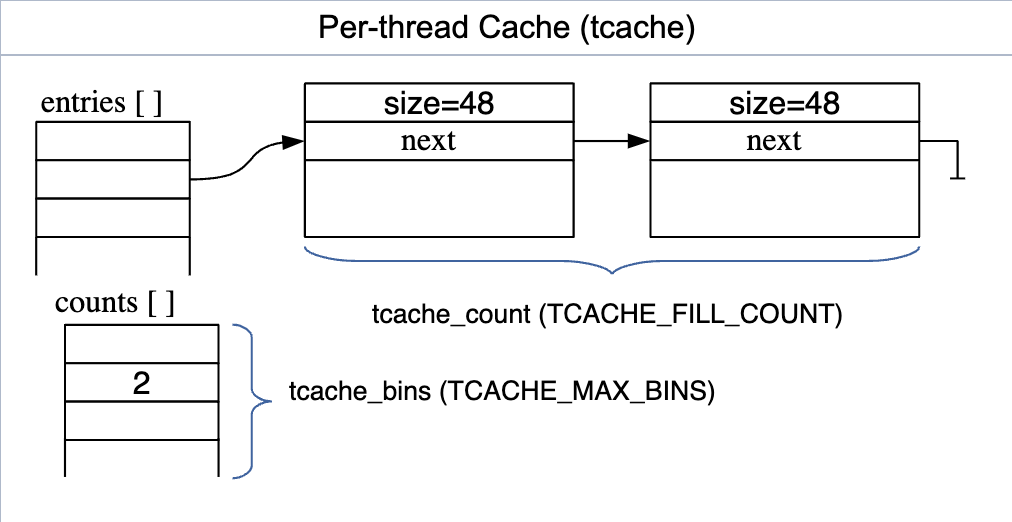
与Fast bins类似,tcache根据Chunk大小将其放入不同的桶中。同一个桶中只存放一种大小的Chunk,并以单链表的形式进行连接。与Fast bins不同的是,tcache中每个桶的容量都是有限的。为了快速取得每个桶中的Chunk数,每个桶还维护了一个对应的计数域。另外,这些桶中存储的指针都直接指向payload,而不是Chunk,因此在分配和释放时无需对这些指针进行修改。
malloc 分配与回收算法
malloc分配与回收流程可大致表示为下面的流程。
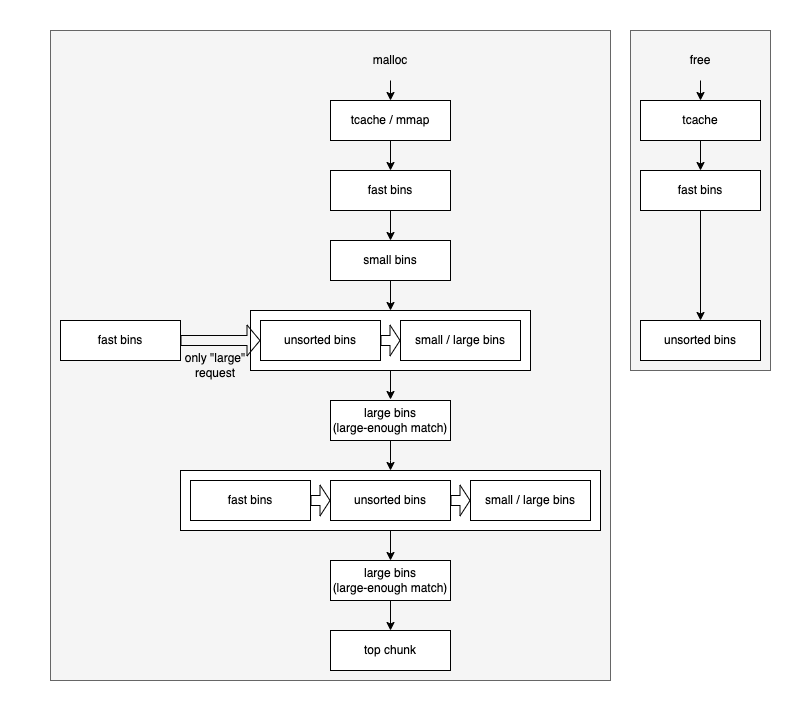
分配算法
分配部分流程为:
首先从tcache中搜索大小匹配的空闲块,如果分配超大Chunk,则直接通过mmap向操作系统申请内存块。
从fast bins中搜索大小匹配的空闲块,并摘出空闲Chunk填入tcache。
从small bins中搜索大小匹配的空闲块,并摘出空闲Chunk填入tcache。
如果分配的Chunk较大,便将fast bins填入unsorted bins,并在这个过程中进行可行的合并。
从unsorted bins中摘取空闲Chunk,合并到small bins或large bins中,在这个过程中发现匹配的空闲Chunk则直接使用。
对大块分配时,从large bins中搜索空闲Chunk,并在必要时将空闲Chunk进行拆分。
重复4-6的步骤。区别在于,无论请求大小,步骤4都会执行。
将top chunk进行拆分。
回收算法
回收部分流程为:
释放到tcache中,如果是超大Chunk,直接通过unmap返回操作系统。
释放到fast bins中。
释放到unsorted bins中。