基于LFS11.3从源码构建Linux系统-思路篇
为了从源代码构建一个全新的Linux系统,不可避免地涉及到大量的编译工作。而这里的编译,又不仅仅是“编译”,还隐含了“链接”等步骤。如果不仔细设计编译的过程,就容易在这个过程中发生链接错误,导致最终的产物无法正常工作。同时,gcc与glibc又涉及到相互依赖的“循环依赖”问题。
在这里,我们对交叉编译等概念进行介绍,并结合这些概念对LFS编译的思路进行分析。
交叉编译与本地编译
在进行LFS的构建时,我们从宿主系统出发,构建一个新的系统。换句话说,在至少一个阶段中,编译的产物和原本的编译器不会在同一个平台上运行。这种生成的程序不在本机平台上运行的编译过程就叫交叉编译。
与之相对的,大多数时候,我们将程序编译完成后,将直接在本地运行,或移动到具有相同指令集、操作系统的机器上运行。这种为本机平台生成程序的编译过程就叫本地编译。
在LFS的构建中,涉及到多次对编译器的编译,这些过程可以通过下面的表格来概括。我们也将以这个过程为基础,介绍编译过程中的Build和Host等术语。
| 阶段 | Build | Host | Target | 描述 |
|---|---|---|---|---|
| 1 | x86_64-redhat-linux | x86_64-redhat-linux | x86_64-lfs-linux-gnu | 在 pc 上使用 cc-pc 构建交叉编译器 cc1 |
| 2 | x86_64-redhat-linux | x86_64-lfs-linux-gnu | x86_64-lfs-linux-gnu | 在 pc 上使用 cc1 构建 cc-lfs |
| 3 | x86_64-lfs-linux-gnu | x86_64-lfs-linux-gnu | x86_64-lfs-linux-gnu | 在 lfs 上使用 cc-lfs 重新构建并测试它本身 |
上面的Build、Host和Target中的数据均为“CPU-供应商-(内核-操作系统)”三元组的形式,基于autoconf的构建系统使用这些三元组来标识一个系统的类型。在大多数系统上可以通过 gcc -dumpmachine 来获取当前系统的三元组。
Build、Host和Target表示了编译中的几个因素。其中:Build表示这一次编译会在哪种系统类型上进行,有时也会被称为host;Host则表示编译得到的程序将在哪种系统上运行;Target则只在编译的对象是编译器的时候有效,它表示这次编译得到的编译器在执行时生成的程序会在哪种系统上运行。
在这样的基础上,我们可以这样判断一个编译过程是否为交叉编译:如果Build与Host一致,则为本地编译;如果不一致,则为交叉编译。(在许多configure脚本中,也会按照这样的逻辑来判断是否采用交叉编译的配置。)
因此,上面的表格中,第2阶段为交叉编译,第1阶段和第3阶段都是本地编译。
编译交叉工具链
通常,宿主系统上的编译器是本地编译器,只能生成在宿主系统上运行的程序。因此,为了得到在新系统上运行的程序,需要首先获得一个交叉编译器。这个交叉编译器能在宿主系统上运行,且编译得到的程序可以在新系统上运行。
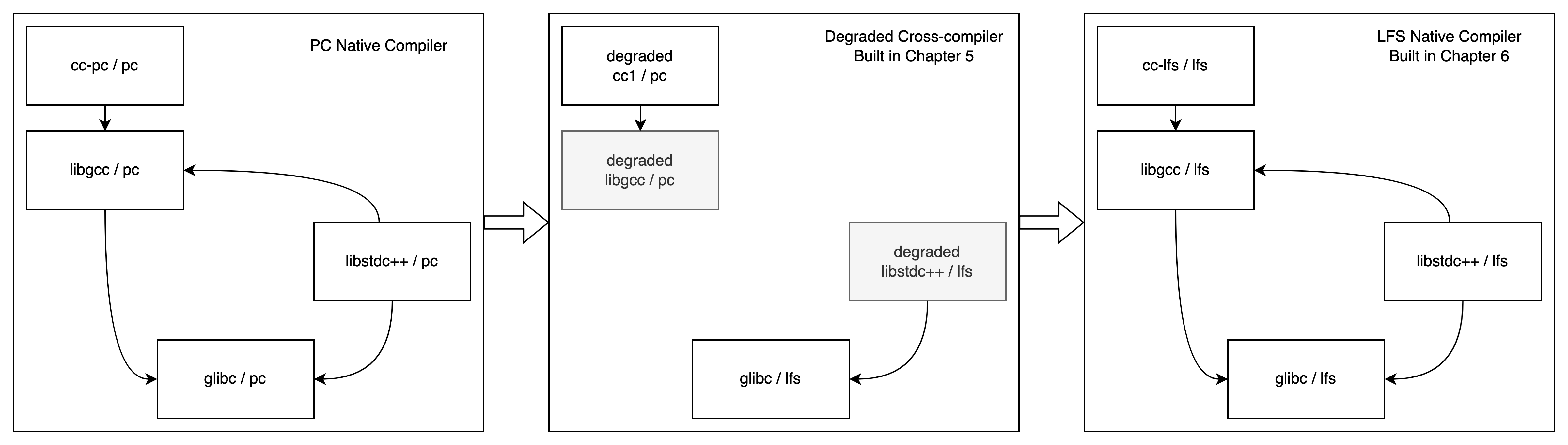
在LFS中,这个交叉编译器是通过宿主系统上的本地编译器编译得来的。这个过程就是前面表格中的第1阶段。也就是通过宿主系统中的本地编译器 cc-pc 构建一个交叉编译器 cc1 ,以便后面使用 cc1 来构建新系统中的程序。
这一章节,我们首先将交叉编译器、交叉链接器等交叉编译工具链构建出来。并将这些工具放在独立的 $LFS/tools 目录中,以便在新系统构建完成后快速清理。由于此时新系统中的 glibc 还未就绪,此时构造的交叉编译器是降级的,也无法构建出功能完整的 libstdc++ 。为了让后续构建的程序能具备相对完成的功能,在降级的交叉工具链构建完成后,我们使用这些降级的工具链构建一个在新系统上工作的完整 glibc 库和一个降级的 libstdc++ 库,并放置在它们的最终位置上。后续编译的临时工具会链接到这些库上,并具备基本的功能。
这一阶段中,有一些使用较多的配置参数,它们确保构建得到的程序为交叉编译器。下面我们对这些参数进行简单介绍:
- –prefix=$LFS/tools : 指定生成的程序的安装目录。这将使程序安装在临时工具目录中。
- –target=$LFS_TGT : 指定与宿主系统不同的target三元组。configure脚本据此可以知道需要采用交叉编译设定。
- –host=$LFS_TGT : 指定目标程序的运行平台。configure脚本据此可以知道需要采用交叉编译设定。
交叉编译临时工具
完成上一章节后,我们有了一个降级的交叉编译工具链、降级的libstdc++库,以及一个功能完整的 glibc。接下来,我们就可以利用这套交叉编译工具链构建一个全新的系统,这个系统中的程序不会链接到宿主系统上。也就是说,这些东西是可以作为独立系统来工作的。
但是,我们没有将新系统中的需要的所有程序全部放在这一阶段去构建。而是只构建了新系统上的本地编译器、本地链接器等本地工具链,以及在一些程序的构建中需要使用的一些工具程序。且这些工具都放置在它们的最终位置上。
在Chroot环境构建新系统里需要的所有软件包
事实上,我们也可以在宿主系统上完成所有软件包的构建和配置,并将设备直接启动到新系统上。在LFS中,没有采用这种方式,而是在宿主系统上构建基本工具后,通过Chroot进入与宿主系统隔离的“最小”状态下的新系统。在这个隔离的环境中,通过本地编译工具链将这个环境中的程序和库全部重新编译并覆盖,同时将所需的其他软件包也编译到新系统中。
采用这种模式,可以带来一些有用的特点:
所有软件都在新环境中使用本地编译器构建而来。这提高了新系统的一致性:在系统构建完成后,再次对软件包进行构建,可以得到一致的程序。
更好的隔离性:在Chroot环境中难以访问宿主系统中的程序、库,这可以保证生成的程序绝对不会依赖于宿主系统。
构建过程本身即可作为新系统的测试。在使用交叉编译时,我们认为在宿主系统上是无法执行交叉编译得到的程序的,也就是无法在宿主系统上对新系统进行测试。而在Chroot环境下构建,则可以很自然地执行构建的程序,从而验证得到的程序的正确性。且新系统的编译本身就是对编译器和之前构建的程序的一种测试。
循环依赖
LFS实际上通过巧妙设计的构建流程,解决了gcc与glibc的“先有鸡还是先有蛋”的问题。
gcc需要依赖于glibc才能实现完整的功能。而glibc需要gcc才能完成编译。这就是在完全从源码构建Linux系统时需要考虑的一个“循环依赖”的问题。
LFS中,这个问题的解决是通过这样一个基础来实现的:gcc可以在没有glibc的情况下实现部分功能,且这部分功能足以编译一个功能完整的glibc。
所以说LFS中“先有gcc还是先有glibc”的答案就是:先有降级的gcc,后有glibc,再有完整的gcc。